もうすぐ入社1年が経つ、こういちです。
普段はPHPしか触っていないので、
今回は、業務で全く扱わない、python、仮想通貨の価格、機械学習などを使ってみました。
自由研究的なあれなので、温かい目で読んであげてください。
環境としては、Jupyter Notebookを使ってpython3係で試していきました。
さっそく仮想通貨の価格情報を取得していきます。
海外の仮想通貨取引所のpoloniexのAPIが、過去の価格情報を取得出来て便利そうなので、
poloniexのAPIを使用していきます。
!pip install https://github.com/s4w3d0ff/python-poloniex/archive/v0.4.6.zip
Macの場合は
「pip」⇒「pip3」
とするようです。
続けて、poloniexのAPIから仮想通貨の価格を取得します。
import poloniex
import time
// poloniexのAPI準備
polo = poloniex.Poloniex()
// 300秒(5分)間隔で100日分読み込む
chart_data = polo.returnChartData('BTC_ETH', period=300, start=time.time()-polo.DAY*100, end=time.time())
このときにperiodに指定できる値は決まっているようで、
300(5分)、900(15分)、1800(1時間)、7200(4時間)、14400(8時間)、 86400(12時間)、polo.DAY(一日)
が指定できるようです。
https://poloniex.com/support/api/
さらに、pandasに先ほどのデータを取り込むと扱いやすいです。
printしてみると。
!pip install pandas
import pandas as pd
// pandasにデータの取り込み
df = pd.DataFrame(chart_data)
print(df)
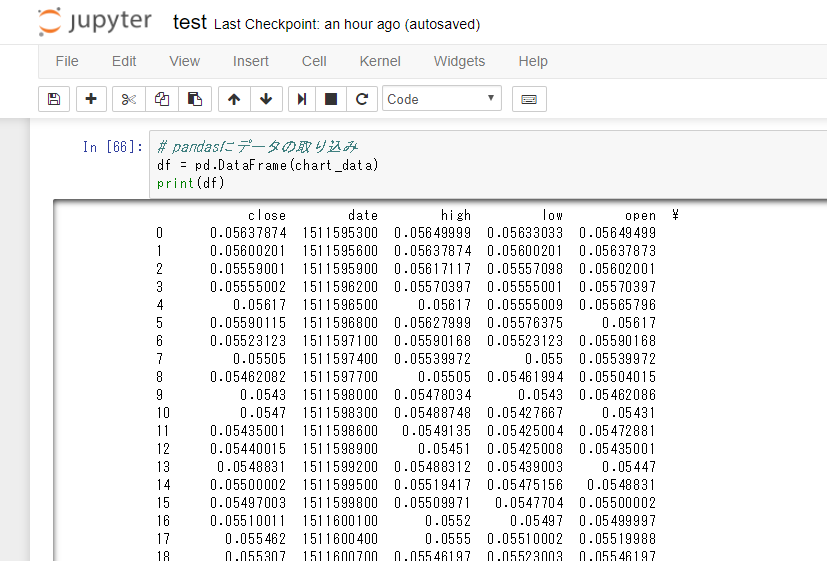
なんということでしょう。
これで価格が簡単に扱えます。
ちなみに、pandasを使わずにprintしてみるとエラーになりました。
”IOPub data rate exceeded.
The notebook server will temporarily stop sending output
to the client in order to avoid crashing it.
To change this limit, set the config variable”
ふむぅ。
Jupyter notebookのconfigいじれば何とかなるようですが、
まあpandas使ったら問題ないのでここは触れないでおきましょう。
次は、機械学習モデルに渡す、入力変数xと出力変数tを定義していきます。
今回は、
入力変数に「現在価格、6時間移動平均との乖離率、1時間移動平均との乖離率、5分前価格との乖離率」
出力変数に「上昇or下落」
の情報をセットしました。
移動平均の計算時にもpandasが活躍してくれました。
パンダつよい?????
// APIからString型として受け取るため、float型に変換
data = df['close'].astype(float)
// データを入力変数xと出力変数tに切り分け
x, t = [], []
data_count = len(data)
// 移動平均線の情報がないこの数だけ、準備する入出力変数がずれ込む
start = 12*6
MA_6h = pd.Series.rolling(df['close'], start).mean()
MA_1h = pd.Series.rolling(df['close'], 12).mean()
x = []
t = []
for n in range(start-1, data_count-1):
// 6時間の平均、1時間の平均、5分前 それぞれの価格からの乖離率を計算
now_for_MA_6h = data[n] / MA_6h[n] - 1
now_for_MA_1h = data[n] / MA_1h[n] - 1
now_for_before_5_minutes = data[n] / data[n-1] - 1
// 入力変数に現在価格と乖離率を準備(それぞれの値が、おおよそ±1.0の範囲に収まるような適当な係数をかけてます)
_x = [data[n], now_for_MA_6h * 25, now_for_MA_1h * 50, now_for_before_5_minutes * 100]
// 出力変数に「0 or 1(下落or上昇)」を準備(5分後の価格が上がるか下がるか予想させる)
_t = 1 if data[n] <= data[n+1] else 0
// 計算用のリスト(x, t)に追加していく
x.append(_x)
t.append(_t)
入力変数、出力変数が、想定の数と同じだけ存在するかprintしてみます。
// データ数確認
print(data_count - start)
print(len(x))
print(len(t))
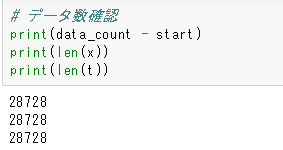
問題なさそうです。
続いて入力変数と出力変数を、それぞれ訓練用と検証用に振り分けます。
// 75%を訓練用、25%を検証用
N_train = int((data_count - start) * 0.75)
x_train, x_test = x[:N_train], x[N_train:]
t_train, t_test = t[:N_train], t[N_train:]
機械学習のライブラリであるscikit-learnを読み込み、線形回帰のモデルで学習します。
こんなコード書くだけで学習してくれます。めっちゃ簡単。
// scikit-learnのサポートベクターマシンを読み込み
from sklearn import svm
// 線形サポートベクターマシンを準備
clf = svm.LinearSVC()
// 訓練データを使ってモデルの学習
clf.fit(x_train, t_train)
test用データの入力変数をつかって予測値を用意します。
// 予測値
predicted = clf.predict(x_test)
予測値と実測値が同じか調べて、正解率を計算し、printします。
result = []
for n in range(len(t_test)):
_result = True if t_test[n] == list(predicted)[n] else False
result.append(_result)
matched_count = len(['matched!!!' for n in result if n==True])
matched_percent = matched_count / len(predicted)
print(matched_percent)
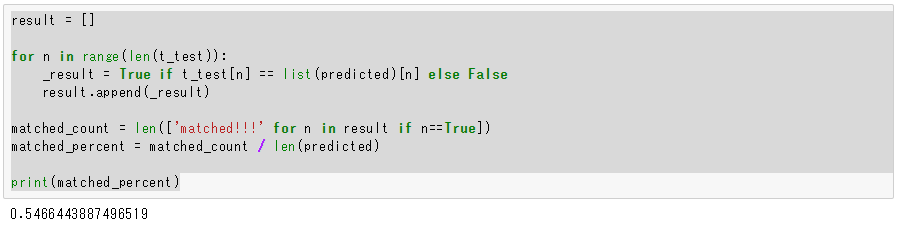
およそ54.66%の正解率。
それっぽい数字が出た。
最後に、不安なので想定通り値が入っているか確認。
// 実測値
print(t_test[-20:])
// 予測値
print(list(predicted)[-20:])
// 正解か不正解か
print(result[-20:])

同じ部分はTrue。
うん、問題ない!
この記事を書くにあたって下記の記事を参考にしました。
https://qiita.com/yoshizaki_kkgk/items/79f4056901dd9c059afb
コメントを残す